随着多媒体信息在移动和手持设备中的广泛应用,人们开始研究低复杂性、对硬件要求较低的多媒体加密技术。如今,Huffman编码用于许多音视频文件格式(如MPEG4.JPEG.MP3等。),基于Huffman编码的低复杂性的多媒体加密技术逐渐进入人们的研究视野。
一、MHT加密方法。
许多音视频格式,如JPEG.MP3.MPEG的熵编码阶段,都是根据预先确定的Huffman代码表进行编码和数据流转换,在此过程中可以添加一些加密措施。最早的MHT加密方案是在Huffman代码表中选择一些合适的表来编码数据流,然后对其选择的方法和编码顺序进行保密,从而达到加密的目的。由于普通培训获得的Huffman代码表数量有限,加密的安全性很低。MHT算法是在不改变其代码树结构的情况下,增加加密空间,提高加密的安全性。其基本思路是,首先通过培训获得与多媒体数据相对应的基本Huffman代码表,然后通过基本代码表以某种方式转换代码表,选择部分代码表进行数据流加密。选择方法是使用已生成的密钥。MHT的加密过程如下:
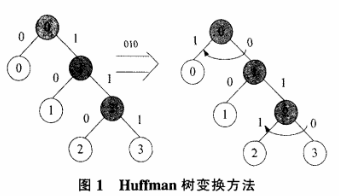
a)先拿到基本的Huffman码表,再对其进行变换,再得到2k码表,依次标记为012K-1。
改变方法如图l所示。如果基本的Huffrnan代码树有t叶,则有t-l内部节点和相应的01标记对。首先,随机生成t-l比特的随机序列,每个节点对应于代码树的内部节点。如果序列位置是O,则交换相应节点的01标记,如果是l,则不交换。
b)生成伪随机向量P=(p1,p2..,Pn)作为密钥,pi为0-2&-1范围内的k比特整数。
c)用第Pi个Huff-man码表编码原始数据的第一段数据,Pi值为p(i-l(madn)+l。
这种方法只需要通过训练获得少量的基本Huffman表,然后通过基本表转换获得大量的Huffman表,比通过训练获得大量的Huffman表更简单。如果原来的Huffinan树有t-l内节点,我们有t-l选择来决定是否改变每个内节点对应的标记对,因此可以生成2t-1个不同的Huffman树,改变后的Huffman树与原来的Huffman树结构相同,对数据流的编码效率没有影响。与直接进行Huffinan编码相比,MHT方案基本上没有增加太多额外的计算量,同时也增加了一定的安全性,但需要消耗一些额外的内存空间来存储表。
二、MHT安全分析。
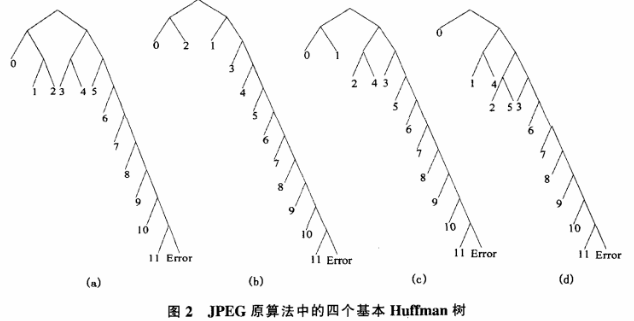
以JPEG算法中加密DC(DC分量)系数时对应的Huffman编码树为例。
唯密文攻击:在没有任何明确信息的情况下,攻击者只能通过寻找不同密文块之间的统计特征来分析密文,这已经证明通过MHT加密的密文是伪随机序列,接近理想的随机状态,无法使用其统计特征来发誓攻击。如果我们使用穷举攻击的方法,我们可以通过训练得到四个基本代码,如图2所示。如果相应的Huffman树有t码值,则在变换后得到42t-1个Huffman树,并根据矢量P的值选择m码树。总密钥空间为:
总密钥空间大小:![]() 。
。
由于对应的Huffman表有12个代码值,则代码树有II内部节点,我们命令m=8,P=128,则可获得密钥空间大小:
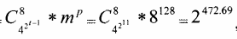
显然是安全的。
已知的明文攻击在这种攻击模型中,攻击者需要找出我们使用的Huffman码表和编码顺序,才能破译密文。如果每个明文符号至少有两个可能的编码长度,则N个符号的密文可能同步大于2~。即使每个Huffman码表只有10个码值,至少也需要数百个密文符号同步,从而重构Huffman码表和编码顺序。由此可见,该算法可以有效抵抗已知的文本攻击。如果攻击者得到一串由Huffman更改的密文B=blb2.6r~,对应明文为S=SIS2.SN,为了将B分为n块Si中对应的编码块,需要考虑CN:1I,复杂度为O(ON-1)。如果你能知道N块的编码长度L,复杂度可以降低到O(LML)。攻击中的危险通常是由于编码时Huffman表选择不当造成的,因为MHT算法中Huffman表的选择是随机的,其中一种可能是选择的muffman树都来自同一棵原始树,每个符号都有相同的编码长度。从表l可以看出,所有符号最多有三种不同的编码长度,复杂度可以降低到0(313)以下,如果给定的明文中没有包含所有这13个符号,复杂度会更低。
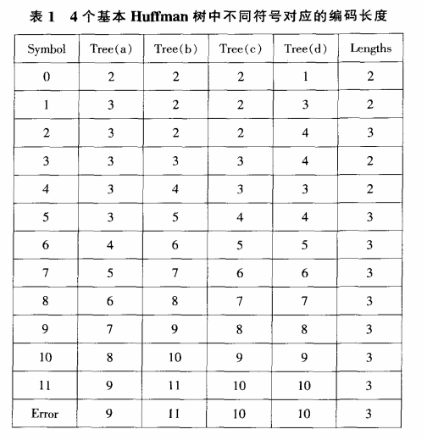
以下情况也容易被攻击者破解:从图2可以看出,大于5的符号有三种不同的编码长度,C树和D树对应的编码长度相同。如果给出两个不同的密文大于5,当它们由同一个代码树编码时,较小符号的代码为Eu,较大符号的代码为Eux(其中E.X为01字符串,u为O或L,u为u的非运算)。然后,如果你知道任何一个大于符号5的代码,你可以很容易地得到小符号的代码,然后你可以用它来判断基本树的四种可能性:a.b.c或d。在第三种情况下,我们可以根据第一个符号编码的第一个比特来判断它是C还是d,从而实现第一个符号的同步。当N=200时,N个符号中不存在1的可能性很小,可以忽略不计。根据上述情况,我们可以认为当N个符号中有两个不同且都大于5的符号时,可以实现第一个符号的同步口。当N=200发生的概率为:
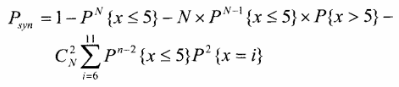
其中,x代表明文符号,P{}代表x的概率。当每个符号的概率由基本的Huffman编码表推导出来时,可以计算出Psyn>0.999,同时可以获取这200个符号的编码信息,构建8个Huffman代码表的一部分。以下信息可以以同样的方式分析。如果密钥长度为128,我们可以成功同步128次。同时,我们可以获得200*128=25600个符号及其编码信息。只要某个符号出现在已知的文本中,就可以恢复相应的Huffman表的编码。由于任何不到10的符号不出现在已知文本中的概率小于0.2%,因此我们可以大概率恢复8个Huffin表的大部分信息,因此只要我们能获得200个已知的明文密文对,我们就可以以以98.7%以上破解密码。
选择明文攻击:在这种情况下,MHT的安全性最弱。如果攻击者能够在密文中插入符号标记并获得相应的输出密文,则完全没有同步问题,这对受保护者非常危险。而且,如果不限制输入明文的长度,我们可以通过每次输入一个符号获得第一个Huffman码表,然后每次输入两个人获得第二个码表以此类推。如果密钥P的长度是128。每个Huffman码表有12个编码符号,只需输入128*12次即可破解密钥P和每个Huffman码表。
通过以上对MHT安全性的分析,NFHT算法存在较大的存储空间消耗。它不能有效地抵抗已知文本和选择明文攻击的缺陷,并分别提出了MHT算法的改进方案。然而,研究发现,这两种改进方案也存在无法抵抗同步攻击的缺陷,并将在一定程度上影响n的编码长度。针对MHT算法的缺陷,我们还提出了改进的HUFFMan表加密方案。
三、改进的MHT算法加密
基本MHT算法是利用变换Huffman树来增大密钥空间从而起到保密性,但这种方法需要大量的存储空间,在某些空问受限的设备上实现可能比较困难,并且如果对表选择不当会有很大的安全漏洞。我们可利用一个伪随机序列对基本Huffman树先进行随机变化然后直接编码,不再进行Huffman树的存储和选择,过程如下:
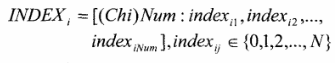
a)经训练得到基本的Huffman码表。
b)利用一输入密钥生成一个伪随机序列P=(Pl,Pl,…,pn)(使用常用的对称加密算法即可),将该序列分隔为如下的格式;
均为每四位隔开,其中Chi为Num的前两比特,目的屉用来选择使用哪个基本Huffinan表进行扰动;Num本身表示扰动节点个数;indexv则表示Num个需要扰乱加密的节点中每个所对应的序号,如图3所示。
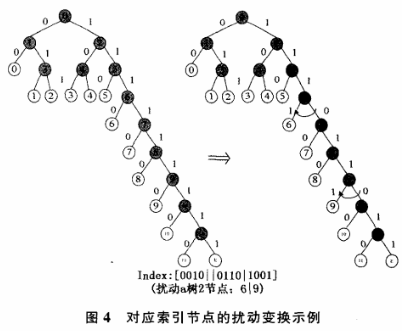
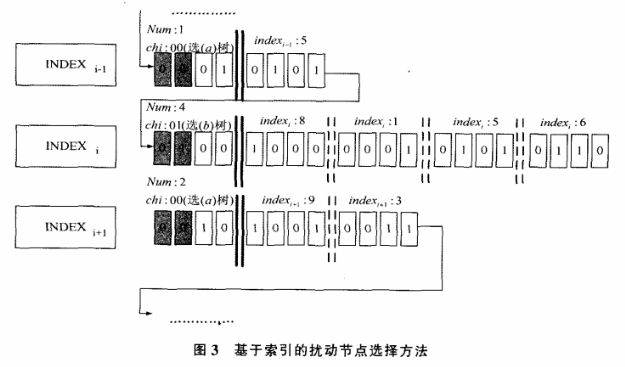 c)扰动的方法就是将对应内部节点上的01互换,其与待加密节点的对应关系及扰动方式如图4所示。
c)扰动的方法就是将对应内部节点上的01互换,其与待加密节点的对应关系及扰动方式如图4所示。
d)原始数据中的第i个节点使用扰动后的Huffman树进行编码。
计算代价分析:这种方法相比MHT方法来讲主要多出了对Huffman树加密扰动的代价,但鉴于对Huffinan树的加密只涉及查找和比特互换操作,开销较小,故计算代价增加不大。而由于其不用存储MHT方法中的大量变换Huffman表,又减小了存储空间的开销。
安全性分析:攻击者在没有密钥的情况下无法得知所对应的各Huffman树,能起到保护作用;MHT方法是先对Huffman变换好,得到固定的树后进行存储,然后从中选掸合适的进行加密,而该方法是直接对Huffman树进行随机扰动,随着序列P的变化每次扰动产生的树不定,且各种扰动的概率没有明显的统计偏向,故能有效抵抗同步攻击;同时,由于编码使用的是扰动后的变换树,即使攻击者得到了原始的四个Huffman树,仍无法通过一些已知明密文对得到二者真正的对应关系来猜测出密钥,从而使选择明文攻击成为不可能。
小知识之Huffman编码
Huffman编码是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
当前位置:首页 >资讯 >多媒体加密技术之huffman编码
多媒体加密技术之huffman编码
![]() zhong hongjun
zhong hongjun
![]() 2月4日, 2022
2月4日, 2022
![]() 0
0